


L'ex-UMR 5612 GRIC a mis sur pied à la fin des années 1990 le projet « Corpus de Français Parlé en Interaction » dans le but de recenser les corpus constitués par les membres de l’équipe depuis la fondation de l’UMR. Ceci avait donné lieu à la réalisation de la base de données CLAPI 1 (cf. section 3. Traitement des corpus dans CLAPI).
L’ACI TTT a permis la conception et le développement d’une nouvelle version de la base CLAPI : CLAPI 2. Le développement en cours vise une amélioration substantielle de la base de données en termes de richesse, de robustesse, d’accessibilité et d’extraction.
L’application informatique CLAPI 2 devra ainsi permettre :
CLAPI 1 comportait une liste de descripteurs dans le but de permettre la localisation des corpus, leur identification ainsi que celle de l’ensemble des personnes ayant participé à leurs constitutions.
Dans le cadre de l’ACI TTT, nous avons enrichi ce travail de description afin de caractériser plus précisément les corpus et leur contenu dans la perspective d’analyses des interactions.
NB : le choix de cette orientation interactionniste implique une description spécifique qui autorise toutefois des exploitations émanant de problématiques différentes (autres domaines de la linguistique, ethnologie, psychosociologie…).
La liste actuelle des descripteurs comporte 75 rubriques hiérarchisées (génériques ou spécifiques) couvrant les champs suivants (cf. Annexe Liste simplifiée des descripteurs) :
Cette liste est provisoirement close pour la mise en ligne de la base mais nous avons prévu son évolution en fonction de l’émergence de nouveaux besoins.
Les spécificités des corpus de LPI à partir desquels la base a été conçue ont conduit à établir deux principes centraux concernant l'utilisation de la base :
§
les
corpus hébergés dans la base CLAPI ne sont pas
donnés à CLAPI
(représenté par son administrateur et son conseil de
gestion), ils restent
contrôlés par leur responsable qui a pleine liberté
pour la définition des
conditions d’accès.
§ l'accès aux corpus n'est pas accordé de façon automatique à toute personne qui consulte la base, étant donné la nature des données hébergées dans CLAPI 2 (informations soumises aux droits du respect de la vie privée, de la diffamation, de la propriété intellectuelle…).
Nous avons donc défini différents types d’utilisateurs, auxquels sont attribués des droits spécifiques (cf. Annexe Tableau des droits d’accès par utilisateur).
Tout accès à un corpus n'est possible que pour un usage strictement scientifique et après signature d'une convention de prêt entre le responsable, le demandeur (une personne physique exclusivement) et l’UMR ICAR. Il est conçu comme une forme d'échange, le demandeur s'engageant, en contre-partie de l'accès au corpus, à fournir des éléments — corpus complémentaire, transcription pour les corpus partiellement transcrits, toilettage, annotation, etc. — qui viendront enrichir la base ; ces éléments font l'objet d'un accord dont les modalités sont spécifiées dans la convention. Les conditions de diffusion et de citation du matériel prêté sont également définies dans ce document.
L’étude et le développement
informatique de la base CLAPI 2
sont pris en charge par le laboratoire ERIC, et font l’objet de la
thèse de
Kamel Aouiche, doctorant financé par l’ACI TTT.
La première phase de cette collaboration a consisté
à analyser
l’existant, CLAPI 1, en étudiant son modèle
conceptuel de données, ses
fonctionnalités et ses limites.
A partir de cette étude et des objectifs définis
ci-dessus, l’équipe ERIC a
élaboré le nouveau modèle conceptuel de
données de CLAPI 2 et listé les
traitements à effectuer. La mise en œuvre de ce projet a
consisté en la
réalisation d’une maquette, qui est actuellement en phase de
tests pour valider
ses fonctionnalités ; à l’issue de cette
étape, l’application définitive
sera développée et mise en ligne.
Les données sont modélisées à l’aide du langage de modélisation UML (Unified Modeling Language). L’utilisation de ce formalisme graphique facilite la prise en compte de modifications ou d’ajouts éventuels au modèle, ainsi que la communication avec l’équipe ICAR.
La figure suivante représente le modèle conceptuel global de CLAPI 2.
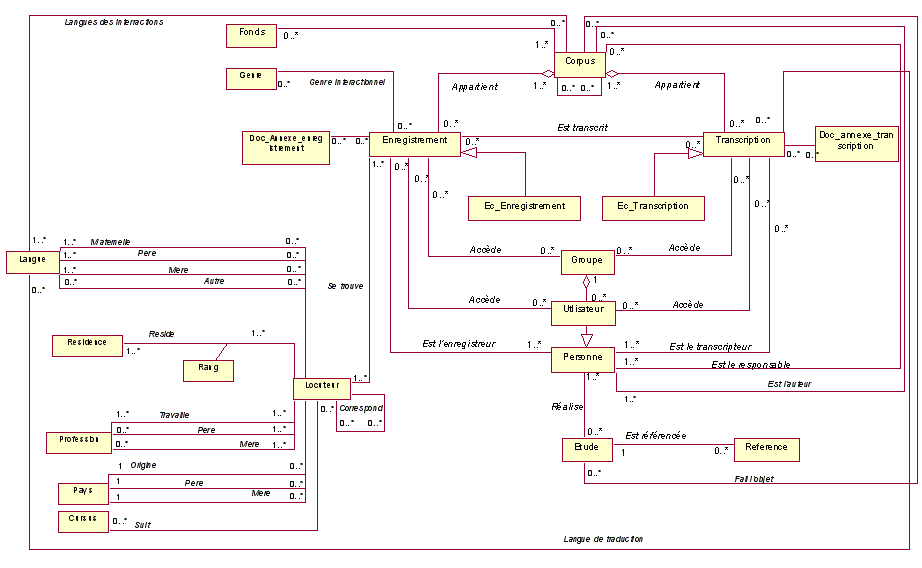
Pour faciliter la lecture de ce modèle, nous l’avons subdivisé en trois parties :
Nous détaillons chacune de ces parties dans les sections suivantes.
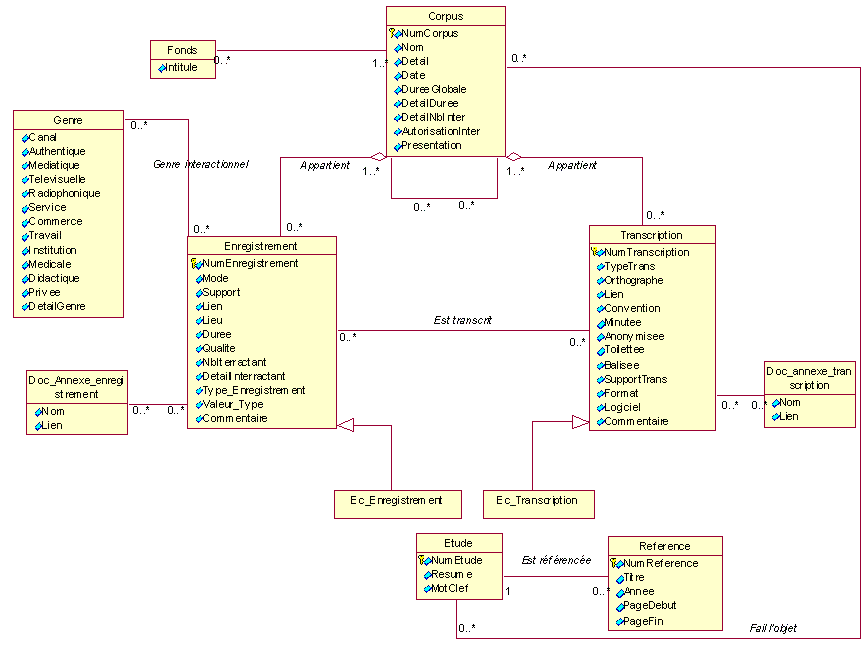
Modèle conceptuel - corpus -
enregistrements – transcriptions – études
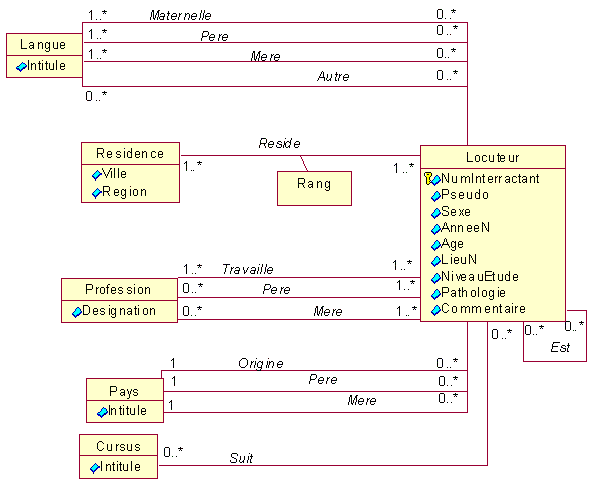
Modèle conceptuel -
locuteurs
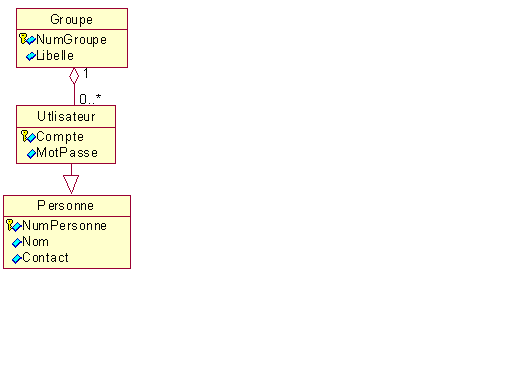
Modèle conceptuel -
personnes - utilisateurs –groupes d’utilisateurs
Identification des utilisateurs de la plate-forme et droits d’accès
Chaque utilisateur possède un compte personnel qui permet au système de l’authentifier. Suivant son groupe d’appartenance, il peut exécuter un ensemble d’actions préalablement définies (consulter un corpus, valider la mise en ligne d’un corpus, octroyer ou retirer des droits d’accès sur des corpus, etc.).
Stockage et mise à jour des corpus
La procédure de soumission en ligne consiste à référencer un corpus et à intégrer ses différentes composantes. Les responsables de corpus peuvent ultérieurement les mettre à jour et valider les ajouts proposés par les utilisateurs contractuels. Des interfaces ont été élaborées afin d’assister les utilisateurs lors de ces différentes opérations.
Interrogation des corpus
La maquette CLAPI 2 peut être interrogée selon deux modes : interrogation sur les descripteurs et sur le « texte intégral » des transcriptions.
La maquette de la plate-forme CLAPI 2 a été réalisée à l’aide d’outils open source : MySQL pour le stockage et la gestion de la base de données, et le langage de programmation PHP pour l’interface. A ce jour, une dizaine de corpus a été référencée dans la base de données CLAPI 2 ; les transcriptions et leurs conventions ont été intégrées ainsi que certains extraits audio ou vidéo. L’implantation définitive de la base permettra le dépôt plus systématique des données primaires.
Le passage de la maquette de CLAPI 2 vers un prototype exploitable nécessite de choisir une architecture matérielle et logicielle adaptée aux contraintes suivantes : puissance, volume de données, temps d’accès, fiabilité.
Le prototype subira une première phase de tests de la stratégie de sécurisation des corpus mise en œuvre. Dans un second temps, ces tests seront étendus à différents utilisateurs afin de valider la plate-forme sur une grande échelle et d’évaluer ses performances en réseau.
 accès réservé aux équipes du projet
accès réservé aux équipes du projet